Scaling laws for distributed random forests: New insights from Helmholtz AI researchers at KIT
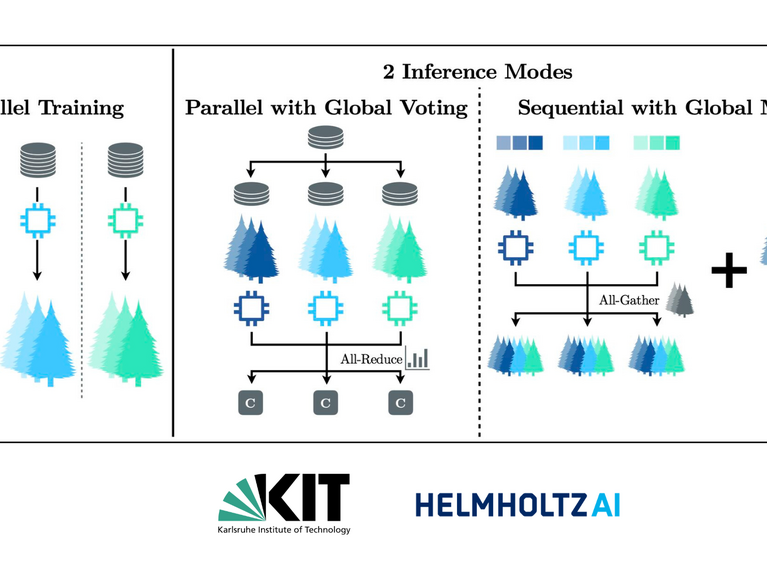
Random forests are among the most widely used machine learning methods for tabular data, valued for their robustness, interpretability, and strong performance across many scientific domains. As datasets and models continue to grow, however, understanding how random forests scale across distributed and federated computing environments has remained an open challenge.
In a new paper published in Transactions on Machine Learning Research, researchers from the Karlsruhe Institute of Technology (KIT) and Helmholtz AI present a comprehensive analysis of the scaling behavior of distributed random forests. The study, titled “Scaling Laws of Distributed Random Forests”, systematically investigates how model performance, training time, and inference efficiency change as compute resources, model size, and data volume are scaled.
Using a hybrid high-performance computing implementation that combines MPI-based distributed computing with shared-memory parallelism, the research demonstrates strong scaling speedups of up to 31.98× and weak scaling efficiencies exceeding 0.96 on up to 64 compute nodes, without any loss in predictive accuracy of the global model. The work further compares different inference strategies, highlighting trade-offs between memory consumption, communication overhead, and data privacy, all of which are key considerations for large-scale and federated AI applications.
Beyond scalability, the paper also explores how distributed and non-IID data affect learning outcomes. The results show that while globally imbalanced data reduces predictive performance, certain forms of moderate local data heterogeneity can partially mitigate these effects, particularly under globally imbalanced data distributions. These findings provide valuable guidance for deploying random forests in real-world federated learning scenarios, where data distributions across sites are rarely identical.
The study was conducted by Katharina Flügel (KIT, Helmholtz AI), Markus Götz (KIT, Helmholtz AI) and Marie Weiel (KIT, Helmholtz AI), in collaboration with Charlotte Debus and Achim Streit at KIT’s Scientific Computing Center. The work was funded by the Helmholtz Association’s Initiative and Networking Fund through the Helmholtz AI platform and carried out on the HoreKa high-performance computing system at KIT.